- TensorFlow queuing and threads – introductory concepts
- The
FIFOQueue– first in, first out QueueRunnersand the Coordinator- A more practical example – reading the CIFAR-10 dataset
- The
string_input_producerandshuffle_batch
One of the great things about TensorFlow is its ability to handle multiple threads and therefore allow asynchronous operations. If we have large datasets this can significantly speed up the training process of our models. This functionality is especially handy when reading, pre-processing and extracting in mini-batches our training data.
The particular queuing operations/objects we will be looking at are FIFOQueue, RandomShuffleQueue, QueueRunner, Coordinator, string_input_producer and shuffle_batch, but the concepts that I will introduce are common to the multitude of queuing and threading operations available in TensorFlow.
TensorFlow queuing and threads – introductory concepts
Threading involves multiple tasks running asynchronously – that is when one thread is blocked another thread gets to run. When we have multiple CPUs, we can also have multi-threading which allows different threads to run at the same time. Unfortunately, threading is notoriously difficult to manage, especially in Python. Thankfully, TensorFlow has come to the rescue and provided us means of including threading in our input data processing.
TensorFlow has released a performance guide which specifically recommends the use of threading when inputting data to our training processes. Their method of threading is called Queuing. Often when you read introductory tutorials on TensorFlow (mine included), you won’t hear about TensorFlow queuing. Instead, you’ll see the following feed_dict syntax as the method of feeding data into the training graph:
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})
Here data is fed into the final training operation via the feed_dict argument. TensorFlow, in its performance guide, specifically discourages the use of the feed_dict method. It’s great for tutorials if you want to focus on core TensorFlow functionality, but not so good for overall performance.
What are TensorFlow queues exactly? They are data storage objects which can be loaded and de-loaded with information asynchronously using threads. This allows us to stream data into our training algorithms more seamlessly, as loading and de-loading of data can be performed at the same time (or when one thread is blocking) – with our queue being “topped up” when required with new data to ensure a steady stream of data. Following are different types of TensorFlow queues.
[back to top]
The FIFOQueue – first in, first out

Here is what is happening in the gif above – first a FIFOQueue object is created with a capacity of 3 and a data type = “float”. An enqueue_many operation is then performed on the queue – this basically loads up the queue to capacity with the vector [0, 0, 0]. Next, the code creates a dequeue operation – where the first value to enter the queue is unloaded. The next operation simply adds 1 to the dequeued value. The last operation adds this incremented number back to the top of the FIFOQueue to “top it up” – making sure it doesn’t run out of values to dequeue. These operations are then run and you can see the result – a kind of slowly incrementing counter.
Let’s have another look at how this works by introducing some real TensorFlow code:
dummy_input = tf.random_normal([3], mean=0, stddev=1)
dummy_input = tf.Print(dummy_input, data=[dummy_input],
message='New dummy inputs have been created: ', summarize=6)
q = tf.FIFOQueue(capacity=3, dtypes=tf.float32)
enqueue_op = q.enqueue_many(dummy_input)
data = q.dequeue()
data = tf.Print(data, data=[q.size()], message='This is how many items are left in q: ')
# create a fake graph that we can call upon
fg = data + 1
In this code example, I’ve created, I first create a random normal tensor, of size 3, and then I create a printing operation so we can see what values have been randomly selected. After that, I set up a FIFOQueue, with capacity = 3 as in the example above. I enqueue all three values of the random tensor in the enqueue_op. Then I immediately attempt to dequeue a value from q and assign it to data. Another print operation follows and then I create basically a fake graph, where I simply add 1 to the dequeued data variable. This step is required so TensorFlow knows that it needs to execute all the preceding operations which lead up to producing data. Next, we start up a session and run:
with tf.Session() as sess:
# first load up the queue
sess.run(enqueue_op)
# now dequeue a few times, and we should see the number of items
# in the queue decrease
sess.run(fg)
sess.run(fg)
sess.run(fg)
# by this stage the queue will be emtpy, if we run the next time, the queue
# will block waiting for new data
sess.run(fg)
# this will never print:
print("We're here!")
All that is performed in the code above is running the enqueue_many operation (enqueue_op) which loads up our queue to capacity, and then we run the fake graph operation, which involves emptying our queue of values, one at a time. After we’ve run this operation a few times the queue will be empty – if we try and run the operation again, the main thread of the program will hang or block – this is because it will be waiting for another operation to be run to put more values in the queue. As such, the final print statement is never run. The output looks like this:
New dummy inputs have been created: [0.73847228 0.086355612 0.56138796]
This is how many items are left in q: [3]
This is how many items are left in q: [2]
This is how many items are left in q: [1]
Once the output gets to the point above you’ll actually have to terminate the program as it is blocked. Now, this isn’t very useful. What we really want to happen is for our little program to reload or enqueue more values whenever our queue is empty or is about to become empty. We could fix this by explicitly running our enqueue_op again in the code above to reload our queue with values. However, for large, more realistic programs, this will become unwieldy. Thankfully, TensorFlow has a solution.
[back to top]
QueueRunners and the Coordinator
The first object that TensorFlow has for us is the QueueRunner object. A QueueRunner will control the asynchronous execution of enqueue operations to ensure that our queues never run dry. Not only that, but it can create multiple threads of enqueue operations, all of which it will handle in an asynchronous fashion.
This makes things easy for us. We have to add all our queue runners, after we’ve created them, to the GraphKeys collection called QUEUE_RUNNERS. This is a collection of all the queue runners, and adding our runners to this collection allows TensorFlow to include them when constructing its computational graph.
This is what the first half of our previous code example now looks like after incorporating these concepts:
dummy_input = tf.random_normal([5], mean=0, stddev=1)
dummy_input = tf.Print(dummy_input, data=[dummy_input],
message='New dummy inputs have been created: ', summarize=6)
q = tf.FIFOQueue(capacity=3, dtypes=tf.float32)
enqueue_op = q.enqueue_many(dummy_input)
# now setup a queue runner to handle enqueue_op outside of the main thread asynchronously
qr = tf.train.QueueRunner(q, [enqueue_op] * 1)
tf.train.add_queue_runner(qr)
data = q.dequeue()
data = tf.Print(data, data=[q.size(), data], message='This is how many items are left in q: ')
# create a fake graph that we can call upon
fg = data + 1
The first change is to increase the size of dummy_input – more on this later. The most important change is the qr = tf.train.QueueRunner(q, [enqueue_op] * 1) operation.
- The first argument in this definition is the queue we want to run – in this case, it is the q assigned to the creation of our FIFOQueue object.
- The next argument is a list argument, and this specifies how many enqueue operation threads we want to create. In this case, my “* 1″ is not required, but it is meant to be illustrative to show that I am just creating a single enqueuing thread which will run asynchronously with the main thread of the program. If I wanted to create, say, 10 threads, this line would look like:
qr = tf.train.QueueRunner(q, [enqueue_op] * 10)The next addition is the
add_queue_runneroperation which adds our queue runner (qr) to theQUEUE_RUNNERScollection.
At this point, you may think that we are all set – but not quite. Finally, we have to add a TensorFlow object called a Coordinator. A coordinator object helps to make sure that all the threads we create stop together – this is important at any point in our program where we want to bring all the multiple threads together and rejoin the main thread (usually at the end of the program). It is also important if an exception occurs on one of the threads – we want this exception broadcast to all of the threads so that they all stop. The session part of our example now looks like this:
with tf.Session() as sess:
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(coord=coord)
# now dequeue a few times, and we should see the number of items
# in the queue decrease
sess.run(fg)
sess.run(fg)
sess.run(fg)
# previously the main thread blocked / hung at this point, as it was waiting
# for the queue to be filled. However, it won't this time around, as we
# now have a queue runner on another thread making sure the queue is
# filled asynchronously
sess.run(fg)
sess.run(fg)
sess.run(fg)
# this will print, but not necessarily after the 6th call of sess.run(fg)
# due to the asynchronous operations
print("We're here!")
# we have to request all threads now stop, then we can join the queue runner
# thread back to the main thread and finish up
coord.request_stop()
coord.join(threads)
The first two lines create a generic Coordinator object and the second starts our queue runners, specifying our coordinator object which will handle the stopping of the threads. We now can run sess.run(fg) as many times as we like, with the queue runners now ensuring that the FIFOQueue always has data in it when we need it – it will no longer hang or block. Finally, once we are done we ask the threads to stop operation (coord.request_stop()) and then we ask the coordinator to join the threads back into the main program thread (coord.join(threads)). The output looks like this:
New dummy inputs have been created: [-0.81459045 -1.9739552 -0.9398123 1.0848273 1.0323733]
This is how many items are left in q: [0][-0.81459045]
This is how many items are left in q: [3][-1.9739552]
New dummy inputs have been created: [-0.03232909 -0.34122062 0.85883951 -0.95554483 1.1082178] This is how many items are left in q: [3][-0.9398123]
We’re here!
This is how many items are left in q: [3][1.0848273]
This is how many items are left in q: [3][1.0323733]
This is how many items are left in q: [3][-0.03232909]
The first thing to notice about the above is that the printing of outputs is all over the place i.e. not in a linear order. This is because of the asynchronous, nonlinear, running of the thread and enqueuing operations. The second thing to notice is that our dummy inputs are of size 5, while our queue only has a capacity of 3. In other words, when we run the enqueue_many operation we, in a sense, overflow the queue. You’d think that this would result in the overflowed values being discarded (or an exception being raised), but if you look at the flow of outputs carefully, you can see that these values are simply held in “stasis” until they have room to be loaded. This is a pretty robust way for TensorFlow to handle things.
Ok, so that’s a good introduction to the main concepts of queues and threading in TensorFlow. Now let’s look at using these objects in a more practical example.
[back to top]
A more practical example – reading the CIFAR-10 dataset
The CIFAR-10 dataset is a series of labeled images which contain objects such as cars, planes, cats, dogs etc. It is a frequently used benchmark for image classification tasks. It is a large dataset (166MB) and is a prime example of where a good data streaming queuing routine is needed for high performance. In the following example, I am going to show how to read in this data using a FIFOQueue and create data-batches using another queue object called a RandomShuffleQueue. The steps are:
- Create a list of filenames which hold the CIFAR-10 data
- Create a
FIFOQueueto hold the randomly shuffled filenames, and associated enqueuing - Dequeue files and extract image data
- Perform image processing
- Enqueue processed image data into a
RandomShuffleQueue - Dequeue data batches for classifier training
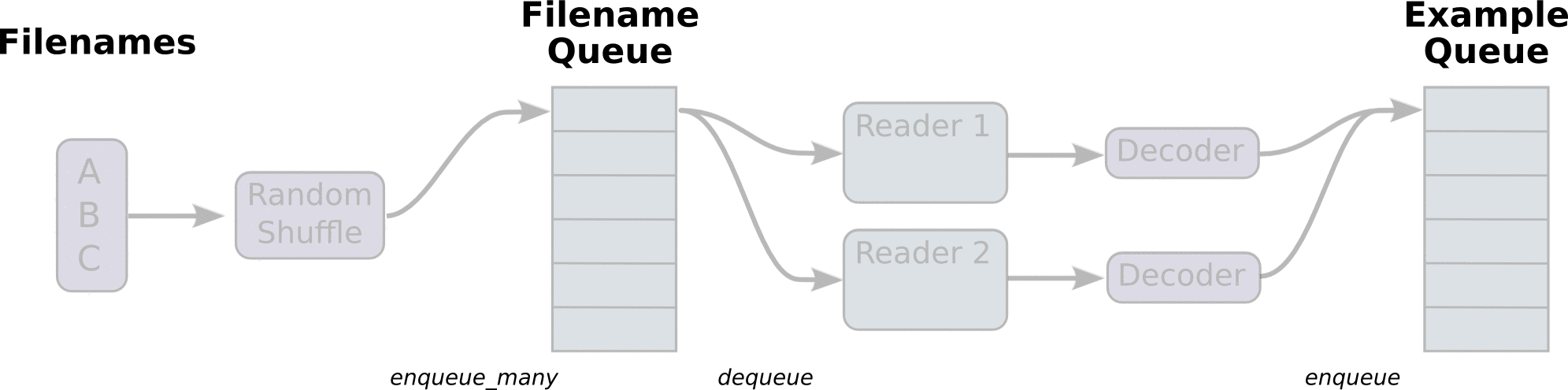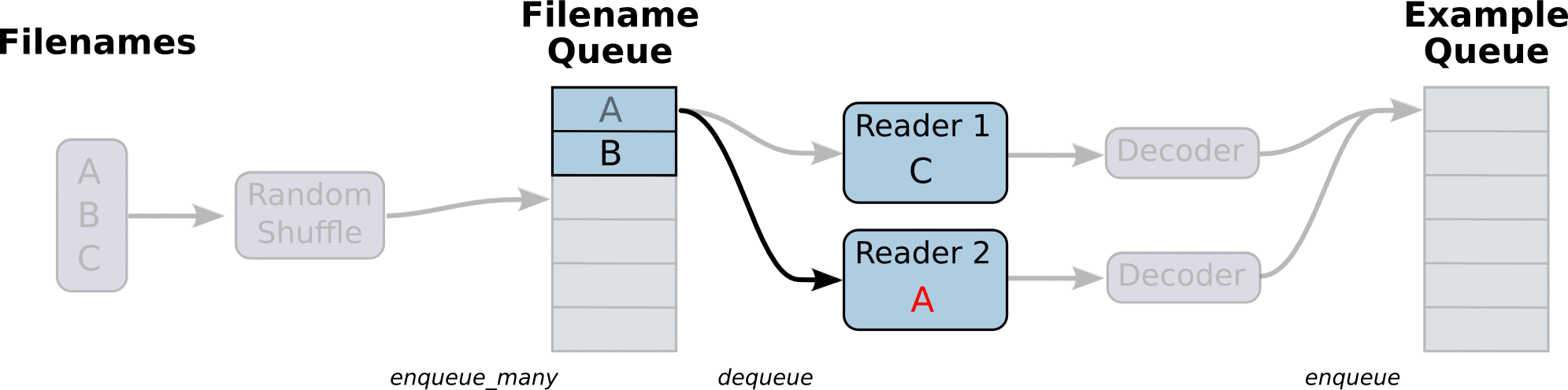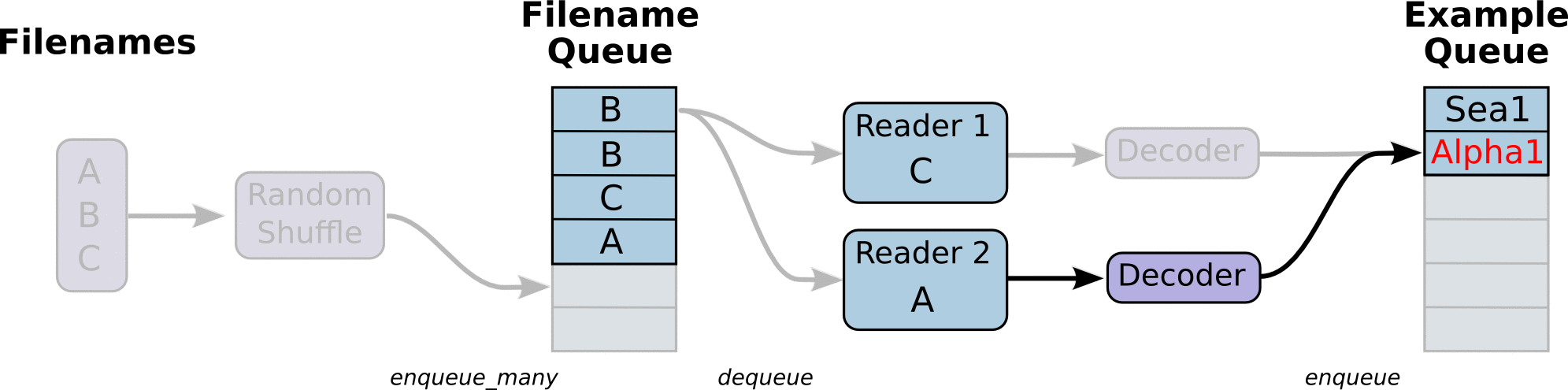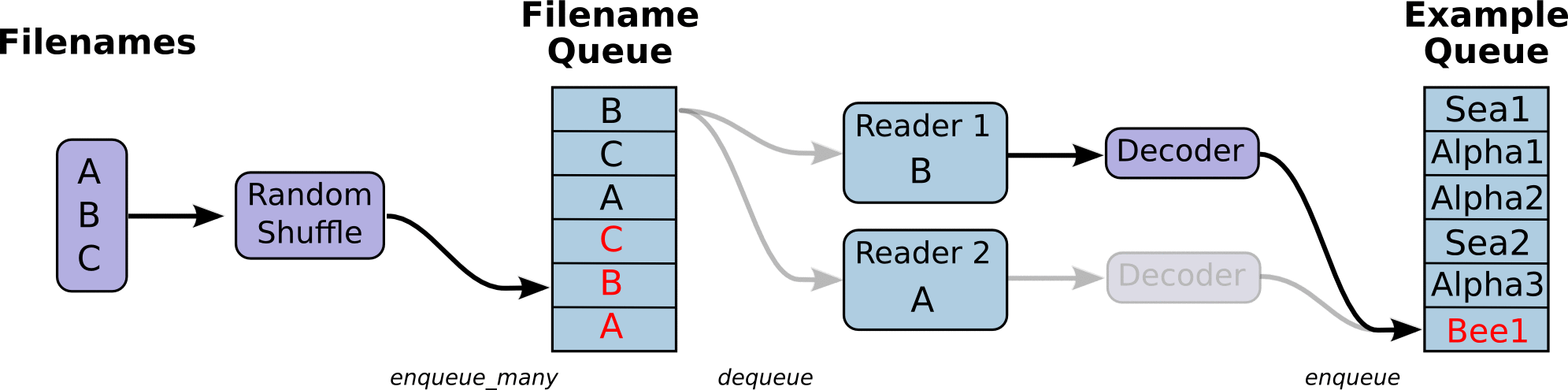
The main flow of the program looks like this:
def cifar_shuffle_batch():
batch_size = 128
num_threads = 16
# create a list of all our filenames
filename_list = [data_path + 'data_batch_{}.bin'.format(i + 1) for i in range(5)]
# create a filename queue
file_q = cifar_filename_queue(filename_list)
# read the data - this contains a FixedLengthRecordReader object which handles the
# de-queueing of the files. It returns a processed image and label, with shapes
# ready for a convolutional neural network
image, label = read_data(file_q)
# setup minimum number of examples that can remain in the queue after dequeuing before blocking
# occurs (i.e. enqueuing is forced) - the higher the number the better the mixing but
# longer initial load time
min_after_dequeue = 10000
# setup the capacity of the queue - this is based on recommendations by TensorFlow to ensure
# good mixing
capacity = min_after_dequeue + (num_threads + 1) * batch_size
image_batch, label_batch = cifar_shuffle_queue_batch(image, label, batch_size, num_threads)
# now run the training
cifar_run(image_batch, label_batch)
The filename queue
First, create a filename list to pull in the 5 binary data files which comprise the CIFAR-10 data set. Then we run the cifar_filename_queue():
def cifar_filename_queue(filename_list):
# convert the list to a tensor
string_tensor = tf.convert_to_tensor(filename_list, dtype=tf.string)
# randomize the tensor
tf.random_shuffle(string_tensor)
# create the queue
fq = tf.FIFOQueue(capacity=10, dtypes=tf.string)
# create our enqueue_op for this q
fq_enqueue_op = fq.enqueue_many([string_tensor])
# create a QueueRunner and add to queue runner list
# we only need one thread for this simple queue
tf.train.add_queue_runner(tf.train.QueueRunner(fq, [fq_enqueue_op] * 1))
return fq
The first thing that is performed in the above function is to convert the filename_list to a tensor. Then we randomly shuffle the list and create a capacity = 10 FIFOQueue. We then enqueue fq with our tensor of randomly shuffled file names and add a queue runner. This is all pretty straightforward and produces a randomly shuffled queue of filenames to dequeue from. We only need one thread to perform this operation, as it is pretty simple. We return the filename queue, fq, from the function.
Next up in the main flow of our program is the read_data function.
[back to top]
The FixedLengthRecordReader
The read_data function takes the filename queue, dequeues file names and extracts the image and label data from the CIFAR-10 data set. Most of the function deals with preprocessing the image data. However, there is a special TensorFlow object that we want to pay attention to:
reader = tf.FixedLengthRecordReader(record_bytes=record_bytes)
result.key, value = reader.read(file_q)
The FixedLengthRecordReader is a TensorFlow reader which is especially useful for reading binary files, where each record or row is a fixed number of bytes. Previously in read_data the number of bytes per record or data file row is calculated and stored in record_bytes. Of particular note is that this reader also implicitly handles the dequeuing operation from file_q (our filename queue). So we don’t have to worry about explicitly dequeuing from our filename queue. The reader will also parse the files it dequeues and return the image data. The rest of the read_data function deals with shaping up the image and label data from the raw binary information. Note that the read_data function returns a single image and label record, of size (24, 24, 3) and (1), respectively. The image size, (24, 24, 3), represents a 24 x 24 pixel image, with an RGB depth of 3.
The next step in the main flow of the program is to setup the minimum number of examples in the upcoming RandomShuffleQueue.
[back to top]
The minimum number of examples in the RandomShuffleQueue
When we want to extract randomized batch data from a queue which is fed by a queue of filenames, we want to make sure that the data is truly randomized across the data set. To ensure this occurs, we want new data flowing into the randomized queue regularly. TensorFlow handles this by including an argument for the RandomShuffleQueue called min_after_dequeue. If, after a dequeuing operation, the number of examples or samples in the queue falls below this value it will block any further dequeuing until more samples are added to the queue. In other words, it will force an enqueuing operation. TensorFlow has some things to say about what our queue capacity and min_after_dequeue values should be to ensure good mixing when extracting random batch samples in their documentation. In our case, we will follow their recommendations:
# setup minimum number of examples that can remain in the queue after dequeuing before blocking
# occurs (i.e. enqueuing is forced) - the higher the number the better the mixing but
# longer initial load time
min_after_dequeue = 10000
# setup the capacity of the queue - this is based on recommendations by TensorFlow to ensure
# good mixing
capacity = min_after_dequeue + (threads + 1) * batch_size
The RandomShuffleQueue
We now want to setup our RandomShuffleQueuewhich enables us to extract randomized batch data which can then be fed into our convolutional neural network or some other training graph. The RandomShuffleQueue is similar to the FIFOQueue, in that it involves the same sort of enqueuing and dequeuing operations. The only real difference is that the RandomShuffleQueue dequeues elements in a random manner. This is obviously useful when we are training our neural networks using mini-batches. The implementation of this functionality is in my function cifar_shuffle_queue_batch, which I reproduce below:
def cifar_shuffle_queue_batch(image, label, batch_size, capacity, min_after_dequeue, threads):
tensor_list = [image, label]
dtypes = [tf.float32, tf.int32]
shapes = [image.get_shape(), label.get_shape()]
q = tf.RandomShuffleQueue(capacity=capacity, min_after_dequeue=min_after_dequeue,
dtypes=dtypes, shapes=shapes)
enqueue_op = q.enqueue(tensor_list)
# add to the queue runner
tf.train.add_queue_runner(tf.train.QueueRunner(q, [enqueue_op] * threads))
# now extract the batch
image_batch, label_batch = q.dequeue_many(batch_size)
return image_batch, label_batch
We first create a variable called tensor_list which is simply a list of the image and label data – this will be the data which is enqueued to the RandomShuffleQueue. We then specify the data types and tensor sizes which match this data and is required as input to the RandomShuffleQueue definition. Because of the large volumes of data, we setup 16 threads for this queue. The enqueuing and adding to the QUEUE_RUNNERS collection operations are things we have seen before. In the final line of the function, we perform a dequeue_many operation and the number of examples we dequeue is equal to the batch size we desire for our training. Finally, the image batches and label batches are returned as a tuple.
All that is left now is to specify the session which runs our operations.
[back to top]
Running the operations
The final function I created in the main flow of the program is called cifar_run:
def cifar_run(image, label):
with tf.Session() as sess:
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(coord=coord)
for i in range(5):
image_batch, label_batch = sess.run([image, label])
print(image_batch.shape, label_batch.shape)
coord.request_stop()
coord.join(threads)
In this function, all I do is run the operations which were passed into this function – image and label. Remember that to execute these operations, the dequeue_many operation must be run for the RandomShuffleQueue along with all the preceding operations in the computational graph (i.e. pre-processing, file name queue etc.). Running these operations returns the actual batch data, and I then print the shape of these batches. I perform 5 batch extractions, but one could perform an indefinite number of these extractions, with the enqueuing and dequeuing all being taken care of via the queue runners. The output looks like this:
(128, 24, 24, 3) (128, 1)
(128, 24, 24, 3) (128, 1)
(128, 24, 24, 3) (128, 1)
(128, 24, 24, 3) (128, 1)
(128, 24, 24, 3) (128, 1)
This output isn’t very interesting – but it shows you that the whole queuing process is working as it should – each time returning 128 examples (128 is our specified batch size) of image and label data. You can also look at each batch and find that the data is indeed randomized as we had hoped it would be. So there you have it, you now know how TensorFlow queuing and threads work.
In the above explanation, for illustrative purposes, I’ve actually shown you the long way of creating filename and random batch shuffle queues. TensorFlow has created a couple of helper functions which reduce the amount of code we need to implement these queues.
[back to top]
The string_input_producer and shuffle_batch
There are two queue helpers in TensorFlow which basically replicate the functionality of my custom functions which utilize FIFOQueue and RandomShuffleQueue. These functions are called string_input_producer which takes a list of filenames and creates a FIFOQueue with enqueuing implicitely provided, and shuffle_batch which creates a RandomShuffleQueue with enqueuing and batch-sized dequeuing already provided. In my main program (cifar_shuffle_batch) you can replace my cifar_filename_queue and cifar_shuffle_batch_queue functions with calls to string_input_producer and shuffle_batch respectively, like so:
# file_q = cifar_filename_queue(filename_list)
file_q = tf.train.string_input_producer(filename_list)
and:
# image_batch, label_batch = cifar_shuffle_queue_batch(image, label, batch_size, num_threads)
image_batch, label_batch = tf.train.shuffle_batch([image, label], batch_size, capacity, min_after_dequeue,
num_threads=num_threads)
Working with restored models
QueueRunner: When TensorFlow is reading the input, it needs to maintain multiple queues for it. The queue serves all the workers that are responsible for executing the training step. We use a queue because we want to have the inputs ready for the workers to operate on. If you don’t have a queue, you will be blocked on I/O and performance will degrade.
Coordindator: This is part of tf.train.Supervisor. It’s necessary because you need a controller to maintain the set of threads (know when main thread should terminate, request stopping of sub-threads, etc).